How to use GPI-Space
This document provides a step-by-step guide on how to create a first GPI-Space application.
Introduction
To create a GPI-Space application and benefit from its automated task management, users define the workflow pattern and the code that makes up each individual task in that workflow. In GPI-Space, a workflow is defined as an abstract Petri net that can be executed by the GPI-Space framework.
Programming Model
To describe and design scalable and parallelizable applications,
GPI-Space leverages the concept of “Petri nets”. Petri nets enable
modeling concurrent and distributed systems. In essence, a Petri net
is a collection of directed arcs connecting “places” and
“transitions”. It can be seen as a bipartite graph with arcs only
going from “place” to “transition” or vice versa, as shown in the
example below. A more formal definition of a Petri net is a tuple
N = (P, T, F, M), where:
Pis a finite set of placesTis a finite set of transitionsMis the “Marking”, a function fromPto the natural numbersN, whereNis the number of tokens in a place- Arcs or flow relations
Femerge fromP --> TorT --> Ponly
Places and transitions define a logical workflow, which can
execute if the transitions are ready to “fire”. A transition can fire
once real values or tokens are put onto places. When the
transition fires, it consumes one token from each input place and
produces one token on each output place.
A Petri net with multiple fire-able transitions inherently enables ‘task parallelism’ and ‘data parallelism’. For example, in the figure below:
- Two
t1transitions can fire simultaneously (data-parallel), each consuming one token at input placep1. - Transition
t1,t2andt3can fire simultaneously (task-parallel), in the figure below.

Architecture
The GPI-Space framework builds on an “agent-worker” architecture, as shown in the figure below. The agent houses the workflow engine and the scheduler. The workers processes that execute the tasks are distributed across the compute nodes. The Remote Interface Daemon (RIFD) on each host coordinates startup and shutdown steps. A distributed shared memory layer (Virtual Memory) completes the GPI-Space ecosystem. The Virtual Memory, Workers and the RIFDs together constitute the Distributed Runtime System (DRTS), as depicted in the figure below.

Example 1: Aggregate Sum
The GPI-Space application design and execution is illustrated with an example computing the aggregate sum over a list of values.
Writing a minimal GPI-Space application requires five steps:
- Setting up the application structure
- Creating a GPI-Space executor
- Designing a workflow
- Creating a workflow launcher
- Compilation and execution
The complete source code files for the example are available here.
Application Structure
A minimal GPI-Space application performs the following actions:
- Loading configuration options
- Initializing a workflow
- Executing the workflow
- Evaluating the workflow result
For our example, these actions can simply be written down in the main function as shown below:
main.cpp
#include <aggregate_sum/parse_parameters_from_commandline.hpp>
#include <aggregate_sum/execute.hpp>
#include <aggregate_sum/Parameters.hpp>
#include <aggregate_sum/Workflow.hpp>
#include <util-generic/print_exception.hpp>
#include <cstdlib>
#include <iostream>
int main (int argc, char** argv)
try
{
// (1) loading configuration options
auto const parameters = aggregate_sum::parse_parameters_from_commandline
(aggregate_sum::execution::options(),
aggregate_sum::Workflow::options(),
argc,
argv
);
// (2) initializing a workflow
aggregate_sum::Workflow const workflow (parameters);
// (3) executing the workflow
auto const results = aggregate_sum::execute (parameters, workflow);
// (4) evaluating the workflow result
return workflow.process (results);
}
catch (...)
{
std::cerr << "FAILURE: " << fhg::util::current_exception_printer() << std::endl;
return EXIT_FAILURE;
}
NOTE:
The exception handling is important for a proper cleanup of a GPI-Space application. The GPI-Space resource infrastructure won’t shutdown properly otherwise.
We load our configuration options via command-line arguments in the function
parse_parameters_from_commandline.
It is a simple wrapper around Boost’s program_options for parsing the GPI-Space execution and the
workflow options.
The following shows parse_parameters_from_commandline’s header file:
parse_parameters_from_commandline.hpp
#pragma once
#include <aggregate_sum/Parameters.hpp>
namespace aggregate_sum
{
Parameters parse_parameters_from_commandline
(ParametersDescription const& execution_options,
ParametersDescription const& workflow_options,
int argc,
char** argv
);
}
The types ParametersDescription and Parameters are type definitions of boost::program_options::options_description
and boost::program_options::variables_map respectively and are provided by Parameters.hpp.
parse_parameters_from_commandline’s implementation is also straight forward.
First, an options variable is initialized.
Next, the command-line arguments are parsed and the result is returned as a Parameters object.
parse_parameters_from_commandline.cpp
#include <aggregate_sum/parse_parameters_from_commandline.hpp>
#include <boost/program_options.hpp>
#include <cstdlib>
#include <iostream>
namespace aggregate_sum
{
Parameters parse_parameters_from_commandline
(ParametersDescription const& driver_opts,
ParametersDescription const& workflow_opts,
int argc,
char** argv
)
{
namespace po = boost::program_options;
ParametersDescription options;
options.add_options()("help", "this message");
options.add (driver_opts);
options.add (workflow_opts);
Parameters parameters;
po::store ( po::command_line_parser (argc, argv)
. options (options)
. run()
, parameters
);
if (parameters.count ("help"))
{
std::cout << options << std::endl;
std::exit (EXIT_SUCCESS);
}
parameters.notify();
return parameters;
}
}
The header file Parameters.hpp only contains the typedefs mentioned above which are used within
multiple classes.
Parameters.hpp
#pragma once
#include <boost/program_options/options_description.hpp>
#include <boost/program_options/variables_map.hpp>
namespace aggregate_sum
{
using ParametersDescription = boost::program_options::options_description;
using Parameters = boost::program_options::variables_map;
}
NOTE
GPI-Space execution and workflow options can be combined in a single place. For the purpose of this tutorial they are split to better distinguish between the different options.
GPI-Space Executor
The GPI-Space executor (also known as driver) is the piece of code which initializes the GPI-Space resource infrastructure and executes workflows. Generally, the design of the driver depends on the application using GPI-Space.
For the Aggregate Sum example, we implement the following minimal execute function:
execute.hpp
#pragma once
#include <aggregate_sum/Parameters.hpp>
#include <aggregate_sum/WorkflowResult.hpp>
namespace aggregate_sum
{
class Workflow;
namespace execution
{
ParametersDescription options();
}
WorkflowResult execute (Parameters, Workflow const&);
}
GPI-Space comes with pre-defined options using Boost’s program_options.
The function execution::options() creates a ParametersDescription grouping those options.
The topology option is a convenience option for this example containing a string defining the
GPI-Space resource infrastructure topology.
The execute function first determines the application’s root install path required for locating
the workflow related files.
Afterwards, it processes the passed Parameters object to initialize the GPI-Space resource
infrastructure.
Finally, the GPI-Space client object takes a workflow object and the corresponding input map of
type ValuesOnPorts, and submits a job on the previously initialized resources.
execute.cpp
#include <aggregate_sum/execute.hpp>
#include <aggregate_sum/Workflow.hpp>
#include <drts/client.hpp>
#include <drts/drts.hpp>
#include <drts/scoped_rifd.hpp>
#include <util-generic/executable_path.hpp>
#include <boost/filesystem/path.hpp>
#include <string>
namespace aggregate_sum
{
namespace execution
{
ParametersDescription options()
{
namespace po = boost::program_options;
ParametersDescription driver_opts ("Worker Topology");
driver_opts.add_options()("topology", po::value<std::string>()->required());
driver_opts.add (gspc::options::installation());
driver_opts.add (gspc::options::drts());
driver_opts.add (gspc::options::logging());
driver_opts.add (gspc::options::scoped_rifd());
return driver_opts;
}
}
WorkflowResult execute (Parameters parameters, Workflow const& workflow)
{
auto const aggregate_sum_installation_path
(fhg::util::executable_path().parent_path().parent_path());
gspc::installation installation (parameters);
gspc::scoped_rifds rifds(gspc::rifd::strategy {parameters},
gspc::rifd::hostnames {parameters},
gspc::rifd::port {parameters},
installation);
gspc::set_application_search_path
(parameters, aggregate_sum_installation_path / "lib");
gspc::scoped_runtime_system drts (parameters,
installation,
parameters.at ("topology").as<std::string>(),
rifds.entry_points());
gspc::workflow const workflow_obj
(aggregate_sum_installation_path / "pnet" / "aggregate_sum.pnet");
return gspc::client {drts}.put_and_run (workflow_obj, workflow.inputs().map());
}
}
The ValuesOnPorts class is the last element required for the GPI-Space executor.
It’s a simple type wrapper class for managing the tokens on ports mappings.
Value is a boost::variant type of all the allowed token nets in a Petri net.
ValuesOnPorts.hpp
#pragma once
#include <we/type/value.hpp>
#include <map>
#include <string>
namespace aggregate_sum
{
class ValuesOnPorts
{
public:
using Key = std::string;
using Value = pnet::type::value::value_type;
using Map = std::multimap<Key, Value>;
ValuesOnPorts (Map map);
Map const& map() const;
protected:
Map _values_on_ports;
};
}
The implementation of ValuesOnPorts shown below is similarly unspectacular:
ValuesOnPorts.cpp
#include <aggregate_sum/ValuesOnPorts.hpp>
namespace aggregate_sum
{
ValuesOnPorts::ValuesOnPorts (Map map) : _values_on_ports (map) {}
ValuesOnPorts::Map const& ValuesOnPorts::map() const
{
return _values_on_ports;
}
}
Workflow
Now that we have our executor code ready, we continue with designing our workflow.
For our example, we will compute the Aggregate Sum of a list of values represented
by the following Petri net:

In GPI-Space, Petri nets are represented in a XML format called XPNET.
This Petri net description format is discussed further down below.
The following code describes our Petri net in the XPNET format:
aggregate_sum.xpnet
<defun name="aggregate_sum">
<in name="values" type="int" place="values"/>
<out name="sum" type="int" place="sum"/>
<net>
<place name="values" type="int"/>
<place name="sum" type="int">
<token>
<value>0</value>
</token>
</place>
<transition name="aggregate">
<defun>
<in name="value" type="int"/>
<inout name="sum" type="int"/>
<module name="aggregate_sum" function="plus (value, sum)">
<code><![CDATA[
sum += value;
]]></code>
</module>
</defun>
<connect-in port="value" place="values"/>
<connect-inout port="sum" place="sum"/>
</transition>
</net>
</defun>
NOTE
The
executefunction adds the extension.pnetto the workflow name intentionally..pnetis generated by thepnetccompiler from a.xpnetinput file.
Workflow Launcher Setup
With our driver and workflow in hand, it is time to write the application dependent pieces of
the code organized in the class Workflow:
Workflow.hpp
#pragma once
#include <aggregate_sum/Parameters.hpp>
#include <aggregate_sum/ValuesOnPorts.hpp>
#include <aggregate_sum/WorkflowResult.hpp>
namespace aggregate_sum
{
class Workflow
{
public:
static ParametersDescription options();
Workflow (Parameters const& parameters);
ValuesOnPorts inputs() const;
int process (WorkflowResult const& result) const;
private:
int _N;
};
}
Similar to execution::options(), the static method Workflow::options() is defining workflow
specific configuration options.
In this example, we require the number of tokens N to be generated in the input port.
The constructor is taking care of extracting N from the passed Parameters.
The remaining methods are straight forward.
inputs() is mapping token values from 0 to N to the port named values defined in the Petri
net above.
process() is simply extracting the aggregate sum result from the WorkflowResult object and
printing it to the console.
Workflow.cpp
#include <aggregate_sum/Workflow.hpp>
#include <iostream>
namespace aggregate_sum
{
ParametersDescription Workflow::options()
{
namespace po = boost::program_options;
ParametersDescription workflow_opts ("Workflow");
workflow_opts.add_options()("N", po::value<int>()->required());
return workflow_opts;
}
Workflow::Workflow (Parameters const& args)
: _N (args.at ("N").as<int>())
{}
ValuesOnPorts Workflow::inputs() const
{
ValuesOnPorts::Map values_on_ports;
for (int i = 1; i <= _N; ++i)
{
values_on_ports.emplace ("values", i);
}
return values_on_ports;
}
int Workflow::process (WorkflowResult const& results) const
{
auto const& sum = results.get<int> ("sum");
std::cout << "Aggregate Sum: " << sum << std::endl;
return sum == _N * (_N + 1) / 2 ? EXIT_SUCCESS : EXIT_FAILURE;
}
}
The last class that is still missing now WorkflowResult.
This class is based on ValuesOnPorts and adds error checking functionality for extracting values
from ports.
The method of interest here is the get method which takes a key value as input, verifies there
is exactly one occurence in the output, and finally returns the value associated to the port with
the corresponding key.
WorkflowResult.hpp
#pragma once
#include <aggregate_sum/ValuesOnPorts.hpp>
#include <cstddef>
namespace aggregate_sum
{
class WorkflowResult : public ValuesOnPorts
{
public:
using ValuesOnPorts::ValuesOnPorts;
// asserts there is exactly one occurence of key
template<typename T> T const& get (Key key) const;
private:
void assert_key_count
( Key key
, std::size_t expected_count
) const;
template<typename T, typename TypeDescription>
T const& get_impl (Key key, TypeDescription type_description) const;
};
template<> int const& WorkflowResult::get (Key key) const;
}
The get method is specialized for the type int as it is the only possible token value in our
example.
This approach is a good practice for developing workflows in order to catch type errors as early
as possible.
The implementation details of WorkflowResult can be seen below:
WorkflowResult.cpp
#include <aggregate_sum/WorkflowResult.hpp>
#include <we/signature_of.hpp>
#include <we/type/signature/show.hpp>
#include <we/type/value/show.hpp>
#include <util-generic/cxx17/holds_alternative.hpp>
#include <util-generic/join.hpp>
#include <boost/format.hpp>
#include <stdexcept>
namespace aggregate_sum
{
void WorkflowResult::assert_key_count
( Key key
, std::size_t expected_count
) const
{
auto const count (_values_on_ports.count (key));
if (count != expected_count)
{
throw std::logic_error
(str ( boost::format ("Expected count '%1%' for key '%2%': Got count '%3%' in { %4% }")
% expected_count
% key
% count
% fhg::util::join
( _values_on_ports, ","
, [] (auto& os, auto const& kv) -> decltype (os)
{
return os << kv.first << " = " << pnet::type::value::show (kv.second);
}
)
)
);
}
}
template<typename T, typename TypeDescription>
T const& WorkflowResult::get_impl (Key key, TypeDescription type_description) const
{
assert_key_count (key, 1);
auto const& value (_values_on_ports.find (key)->second);
if (!fhg::util::cxx17::holds_alternative<T> (value))
{
throw std::logic_error
(str ( boost::format ("Inconsistency: Expected type '%1%'. Got value '%2%' with signature '%3%'.")
% type_description
% pnet::type::value::show (value)
% pnet::type::signature::show (pnet::signature_of (value))
)
);
}
return boost::get<T> (value);
}
template<> int const& WorkflowResult::get (Key key) const
{
return get_impl<int> (key, "int");
}
}
Compilation and Execution
The compilation of GPI-Space applications consists of two steps.
First, the GPI-Space-provided pnetc Petri net compiler takes a .xpnet file and compiles it
into a .pnet file, an internal representation of the Petri net description.
If the Petri net contained modules, a .so file is compiled for each unique module name.
As seen in the execute function, this internal representation file is used to construct
gspc::workflow objects.
Second, the C++ code is compiled into an executable binary.
Both of these steps are combined in the following CMake script:
CMakeLists.txt
cmake_minimum_required (VERSION 3.15)
project (aggregate_sum
LANGUAGES CXX
)
set (CMAKE_CXX_STANDARD 14)
set (CMAKE_CXX_STANDARD_REQUIRED ON)
find_package (GPISpace REQUIRED
COMPONENTS
DO_NOT_CHECK_GIT_SUBMODULES
)
find_package (util-generic REQUIRED)
find_package (util-cmake REQUIRED)
find_package (Boost 1.61.0 REQUIRED
COMPONENTS
filesystem
program_options
)
include (util-cmake/add_macros)
set (BUNDLE_ROOT "libexec/bundle")
bundle_GPISpace (DESTINATION "${BUNDLE_ROOT}/gpispace"
COMPONENTS runtime
)
set (PETRI_NET "${PROJECT_SOURCE_DIR}/workflow/${PROJECT_NAME}.xpnet")
set (COMPILED_PETRI_NET "${PROJECT_BINARY_DIR}/${PROJECT_NAME}.pnet")
set (WRAPPER_DIRECTORY "${PROJECT_BINARY_DIR}/gen")
set (WRAPPER_LIBRARY "${WRAPPER_DIRECTORY}/pnetc/op/lib${PROJECT_NAME}.so")
set (DRIVER_BINARY "${PROJECT_NAME}")
add_custom_command (
COMMAND
GPISpace::pnetc --input="${PETRI_NET}" --output="${COMPILED_PETRI_NET}"
OUTPUT "${COMPILED_PETRI_NET}"
DEPENDS "${PETRI_NET}"
)
add_custom_target (compiled_petri_net
ALL
DEPENDS
"${COMPILED_PETRI_NET}"
)
add_custom_command (
COMMAND
GPISpace::pnetc
--gen-cxxflags="-O3"
--input="${PETRI_NET}"
--output="/dev/null"
--path-to-cpp="${WRAPPER_DIRECTORY}"
COMMAND
+make -C "${WRAPPER_DIRECTORY}"
OUTPUT "${WRAPPER_LIBRARY}"
DEPENDS "${PETRI_NET}"
)
add_custom_target (workflow_library
ALL
DEPENDS
"${WRAPPER_LIBRARY}"
)
extended_add_executable (NAME "${DRIVER_BINARY}"
DONT_APPEND_EXE_SUFFIX
SOURCES
src/parse_parameters_from_commandline.cpp
src/execute.cpp
src/main.cpp
src/Workflow.cpp
src/WorkflowResult.cpp
src/ValuesOnPorts.cpp
INCLUDE_DIRECTORIES PRIVATE include
LIBRARIES PRIVATE Util::Generic
GPISpace::execution
Boost::headers
Boost::filesystem
Boost::program_options
INSTALL
INSTALL_DESTINATION bin
)
bundle_GPISpace_add_rpath (TARGET "${DRIVER_BINARY}" INSTALL_DIRECTORY "bin")
install (FILES
"${COMPILED_PETRI_NET}"
DESTINATION pnet
)
install (FILES
"${WRAPPER_LIBRARY}"
DESTINATION lib
)
Configuration and compilation is performed with following two CMake commands:
cmake \
-D GPISpace_ROOT=<GPISpace-install-dir> \
-D CMAKE_INSTALL_PREFIX=<install-dir> \
-B <build-dir> \
-S <source-dir>
cmake \
--build <build-dir> \
--target install \
-j $(nproc)
After a successful compilation and installation, the aggregate_sum executable will be located in
the install directory.
In order to run a GPI-Space application, a nodefile containing a list of all the hostnames to use
is required.
The same nodefile can be used by multiple applications, so it’s useful to generate it in a central
location (e.g. home directory) and creating an environment variable containing its path.
For testing an application, a nodefile containing the local hostname can be produced with the following
command (the filename doesn’t matter):
hostname > "<nodefile-path>"
Now the aggregate_sum application can be run from within the install directories bin folder with
the command below:
./aggregate_sum \
--gspc-home="<GPISpace-install-dir>" \
--nodefile="<nodefile-path>" \
--rif-strategy=ssh \
--topology="<worker-name>:<num-workers-per-node>" \
--N=<input-size>
, where --rif-strategy is the strategy used to bootstrap the GPI-Space resource infrastructure
(usually ssh).
It uses password- and passphrase-less ssh to the nodes provided by --nodefile.
Non-default ssh keys can be provided by specifying
--rif-strategy-parameters="--ssh-private-key=<private-key-path> --ssh-public-key=<public-key-path>".
Another valid strategy value is local to spin up GPI-Space only on the local system.
And --topology is a convenience option for this example containing a string defining
the GPI-Space resource infrastructure topology.
For this tutorial the form <worker-name>:<num-workers-per-node> is sufficient, where
<worker-name> can be set to an arbitrary non-empty value.
For more information on topology descriptions see
here.
If everything works correctly, calling aggregate_sum with --topology="worker:2" and --N=100
creates an output similar to the one below:
I: starting base sdpa components on 5085b7b0b133 36601 22750...
I: starting top level gspc logging demultiplexer on 5085b7b0b133
=> accepting registration on 'TCP: <<5085b7b0b133:40821>>, SOCKET: <<5085b7b0b133:\00050f>>'
I: starting agent: agent-5085b7b0b133 36601 22750-0 on rif entry point 5085b7b0b133 36601 22750
I: starting worker workers (parent agent-5085b7b0b133 36601 22750-0, 2/host, unlimited, 0 SHM) with parent agent-5085b7b0b133 36601 22750-0 on rif entry point 5085b7b0b133 36601 22750
terminating drts-kernel on 5085b7b0b133 36601 22750: 22768 22774
terminating agent on 5085b7b0b133 36601 22750: 22760
terminating logging-demultiplexer on 5085b7b0b133 36601 22750: 22755
Aggregate Sum: 5050
Congratulations on executing your first GPI-Space program!!!
NOTE
On cluster allocations use the following values for the
--nodefileargument:
- Slurm:
"$(generate_pbs_nodefile)"- PBS/Torque:
"${PBS_NODEFILE}"
XML-Based Workflow Description (XPNET Format)
As promised, we will dive deeper into the XML-based XPNET format, used for defining GPI-Space
workflows, in this section.
For validation in an XML editor the scheme
pnet.xsd can be used.
Each XPNET file implements a function in the form of the <defun> tag.
Therefore, <defun> must be the root tag of every XPNET file.
The name attribute in a <defun> is optional, however it is good practice to name the root tag for
debugging.
A function has a signature described by typed and named ports: <in>, <out>, and/or <inout>.
A function’s implementation has to be one of the following:
<module><expression><net>
Module Functions
<defun name="add">
<in name="lhs" type="int"/>
<in name="rhs" type="int"/>
<out name="output" type="int"/>
<module name="add_module"
function="output add_impl(lhs, rhs)">
<cinclude href="iostream"/>
<code><![CDATA[
int result = lhs + rhs;
std::cout << "output: " << result << std::endl;
return result;
]]></code>
</module>
</defun>
Module functions are written in C/C++ with nearly no restrictions (it can’t be a templated function). If it is possible to write it in a regular program, it can be written as a module. Module functions are meant for heavy duty computations. Therefore, they are executed on GPI-Space workers.
A module function has a mandatory name and function attribute.
The module’s name is used by pnetc for naming the .so file (i.e. lib<module-name>).
Multiple modules are allowed to share the same name, in which case the functions are grouped
within the shared object file.
Module functions can access the ports defined by their parent <defun> tag.
They are used by creating a special function signature of the form
[<out-port-name>] function-name([<in-port-name>|<inout-port-name>]) within the function attribute.
On the C/C++ side, the function parameters will have the same name and type as the ports, where
an <inout> port is equivalent to a type reference argument (e.g. int& value).
Inside the <module> tag, the following needs to be added:
<cinclude href="..."/>: Includes can be added within this tag instead of#include <...>. There can be multiple occurrences of this tag.<code><![CDATA[...]]></code>: The function’s body is contained in this mandatory tag. The current best practice is to use plugins in the function’s body for maximum flexibility.
It is also noteworthy that stdout and stderr are automatically redirected into GPI-Space’s
logging messages, but more on this later.
Expression Functions
<defun name="add">
<in name="lhs" type="int"/>
<in name="rhs" type="int"/>
<out name="output" type="int"/>
<expression>
${output} := ${lhs} + ${rhs}
</expression>
</defun>
Expression functions use a custom expression language supporting some basic operations. Small and fast operations are the prime target for these functions. In contrast to module functions, they are executed by the GPI-Space agent and hence no communication with the workers takes place.
Ports defined by the parent <defun> tag can be accessed within expression functions using the
${<port-name>} syntax.
Assignments are performed with the := notation.
Arithmetic operators have the same syntax as in C/C++.
In the example above, the output port is assigned the result of the addition of the two ports named
lhs and rhs.
There can be empty <expression> tags.
NOTE:
Our
aggregate_sumexample could also have been written using an expression function. Simply replace the<module>tag block in theaggregatetransition with the following:<expression> ${sum} := ${sum} + ${value} </expression>
Net Functions
<defun name="add">
<in name="lhs" type="int" place="left"/>
<in name="rhs" type="int" place="right"/>
<out name="output" type="int" place="result"/>
<net>
<place name="left" type="int"/>
<place name="right" type="int"/>
<place name="result" type="int"/>
<transition name="add_transition">
<defun>
<in name="l" type="int"/>
<in name="r" type="int"/>
<out name="out" type="int"/>
<expression>
${out} := ${l} + ${r}
</expression>
</defun>
<connect-in port="l" place="left"/>
<connect-in port="r" place="right"/>
<connect-out port="out" place="result"/>
</transition>
</net>
</defun>
Net functions are used to describe Petri nets. Opposed to expression and module functions, net functions are not performing computations themselves. Instead, they organize the flow of computations. The execution order of tasks is managed by the workflow engine.
A non-trivial net function contains at least one <place> tag and one <transition> tag.
Places have mandatory name and type attributes.
In the case of a net function, the port definitions of the parent <defun> tag contain an additional
attribute called place, linking the two.
Additionally, a place can have an initial state by providing it with <token> tags.
Each containing a <value> tag with an initial value of matching type (see the Aggregate Sum
example).
Transitions have a name attribute and contain a <defun> tag.
This function’s implementation can be any of the three types: expression, module, net.
Transitions also contain <connect-in>, <connect-out>, and
<connect-inout> tags for each port defined in the <defun> tag.
A connection links ports to places of the parent net function.
Empty expression functions within transitions are useful for moving tokens from one place to another.
GPI-Space Monitoring
As mentioned earlier, GPI-Space automatically redirects stdout and stderr into its logging
messages, but so far we haven’t covered yet how to access the logs.
GPI-Space provides a logger with a console interface and one with a graphical interface.
Both logger executables are located in GPI-Space’s bin directory.
The console logger provides the most basic logging service for GPI-Space called
gspc-logging-to-stdout.exe.
The raw log messages are simply printed out to the console, making this the goto logger if no
graphical session is available.
It is started with the following command:
gspc-logging-to-stdout.exe \
--port=<log-port>
The GUI logger provides a more advanced logging service for GPI-Space called gspc-monitor.
In addition to a more structured log message feed, it also offers a Gantt chart visualization
for tracking the task execution scheduling (see image below).
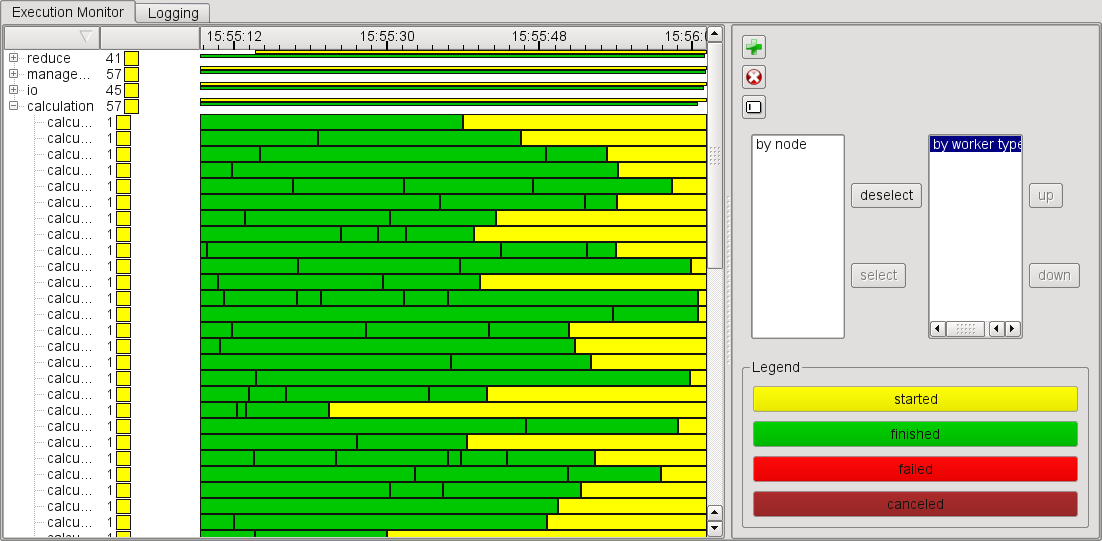
gspc-monitor accepts the same command-line arguments as gspc-logging-to-stdout.exe.
It is started with the following command:
gspc-monitor \
--port=<log-port>
In order to enable logging, the GPI-Space application needs to be launched with the command-line
arguments --log-host and --log-port, providing the connection information for the logger
service.
Before launching an application, the logger already needs to be running.
Failing to do so results in an error.
The following shows how to launch the aggregate_sum example using a localhost logger
listening on port 7777:
./aggregate_sum \
--gspc-home="<GPISpace-install-dir>" \
--nodefile="<nodefile-path>" \
--rif-strategy=ssh \
--topology="<worker-name>:<num-workers-per-node>" \
--N=<input-size> \
--log-host="localhost" \
--log-port=7777
NOTE
The graphical interface logger is only available if GPI-Space is built with the option
GSPC_WITH_MONITOR_APPenabled.